
article





Update zur Schultersituation
Gestern war ich nun beim Arzt um endlich die Auswertung der MRT Bilder der Schulter zu erhalten. Leider stellt es sich doch arger dar, als es der Physio beschrieb („Abnutzungserscheinungen“): Es befinden sich tatsächlich Entzündungen (multiple!) an mehreren Stellen in der Schulter, sowie eine angerissene Bizepssehne, als auch weitere Sehnenproblematiken. Und dazu noch Arthrose im ACG Gelenk. Dort befindet sich nach einer OP aus 2023 immer noch Titan um das zu reparieren. Also, ganz schön was los da.
Nun ist es so, dass ich gern weiterhin Bouldern möchte, und aktiv sein und fit. Aber mit dem derzeitigen Zustand ist das sehr riskant. Bisher ist nix abgerissen. Könnte aber noch kommen.
Deshalb beginne ich jetzt mit einer Eigenbluttherapie 🧛♂️. Klingt komisch. Dabei geht es darum die heilenden Kräfte des Blutplasmas an die Stellen im Gelenk zu bringen, an denen sie benötigt werden (überall! siehe oben), und an die sie sonst nicht so häufig bzw. nicht in der benötigten Konzentration.
Hoffen wir, dass das was bringt. Danach ginge noch Stoßwelle, wenn benötigt.
Your AI Agent is only as good as what it learns
My day job is being an Engineering-Manager-slash-Tech-Lead. I started that in July 2025. The first half year my job was mostly managing humans and working on technical concepts and pitches. I had little time left for working on code. I started using Cursor to work on code and had Cursor rules in place (to instruct the AI on how to work with code, whata rules to follow, what not do do etc.) This worked ok.
I felt like I could start to focus on contributing technical work again.
It really changed once I was able to use Claude Code at work.
In this article I want to share what works best for me, and how the system I use to work on our products using Claude Code get smarter every day.
It all started, when I read this article from Will Larson Learning from Every’s Compound Engineering. I set out to create a reinforcement learning system for my agentic work. Every plan results in work done, which results in learnings captured. Those learnings then get used to improve the plans for the next work item.
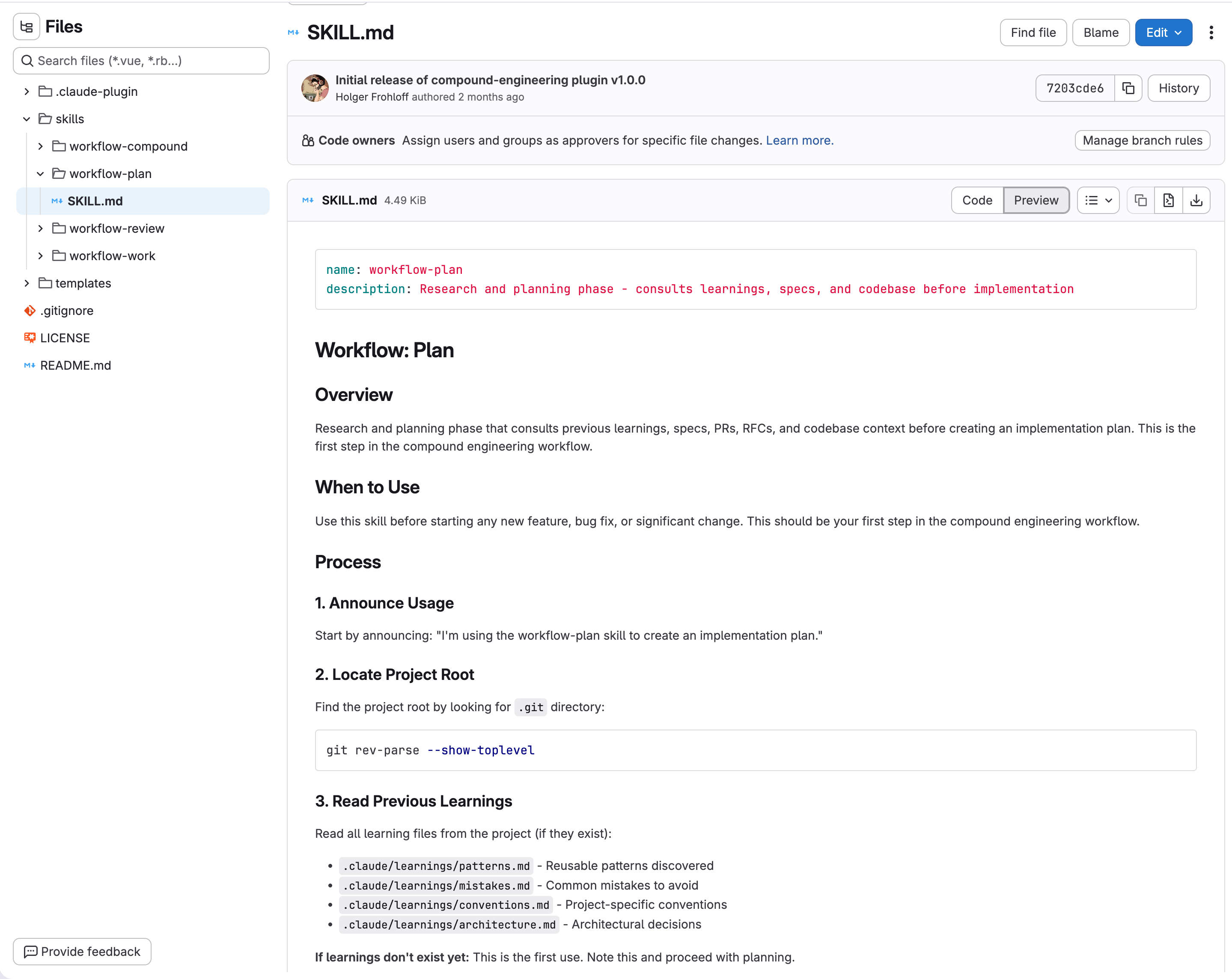
I bet there is stuff to improve on here, but the results I get are good.
Merge Requests / Pull Request
Yesterday, while listening to Avdi Grimm’s podcast I thought about all the knowledge lost not transferred from code reviewers to me the AI. We do have thorough code reviews and sometimes errors, or architectural decisions impact the merge request significantly. Those discussions are only part of the MR and if you are not part of the discussion, you might not see it. The AI certainly does not.
That’s why I created a new skill, that combs through the last x merge requests and finds every relevant discussion by humans (and also by the AI review bot we have). It extracts the learnings and writes them to the project, so my compounding workflow can pick it up next time.
That’s it. Short and sweet. If you use AI agents to work on your code projects, make sure they get “smarter” every time.
Neue Tubeless für BAB25 vom Steppenwolf
Ich habe mir vor über zwei Jahren ein Gravelbike gekauft und das seitdem über 1.100km gefahren. Nun steht am 11.10.25 ein Gravel Event, organisiert vom Steppenwolf an: Berlin—Angermünde—Berlin, 200km durch Brandenburg.
Weil es über sehr viele Kopfsteinpflaster gehen wird, will ich weiterhin tubeless fahren. Aber die Schlappen mussten mal neu gemacht werden, und das hab ich hier in dem kurzen Video mal verwurstelt.
(auch auf Insta www.instagram.com/reel/DO9E…)
Still uncertain about webmentions, Bridgy and connecting Silos to my blog properly
I re-read parts of @manton’s book on webmentions and Bridgy but it still remains unclear to me how to best utilize these systems. I still post to Instagram, for different reasons. Ideally, I would love for my Instagram posts to also be on my blog (maybe even first on the blog, depending on the content(type)). But how do I then connect Instagram replies to be added to my blogpost? Right now I post the url of the blogpost as a comment or description on the Instagram post, but I believe that doesn’t do anything good.
This whole system is still really hard to understand.
Radfahren in der Stadt
Heute morgen auf dem Weg ins Büro ist schon wieder ein kleiner Unfall passiert. Dieses Mal allerdings nicht mir. Ich konnte es in einigem Abstand sehen: Ein Radfahrer fuhr einem Auto hinten drauf, da er nicht mehr rechtzeitig bremsen konnte. Das Auto musste eine Vollbremsung durchführen, da jemand aus einem Gebüsch auf die Straße trat. Nach über 10 Jahren beständigem Radfahren in der Stadt — mit zwischenzeitlich sehr sehr hohem Tempo, und viel zu vielen Unfällen — bin ich mittlerweile zu der Kategorie der Trudler übergegangen. Ich bin der Überzeugung, dass nichts anderes für Radfahrende in Berlin Sinn ergibt. Die Infrastruktur ist katastrophal, Radfeindlich, und wird dank der CDU Regierung wieder schlechter gemacht. Viele Verbesserungen für nicht-Auto fahrende Menschen werden zurückgebaut..
Hier kommt keine echte Pointe mehr, ich bin einfach nur etwas desillusioniert und frage mich, warum Menschen die Stadt nicht menschenfreundlicher gestalten möchten. Kopenhagen macht es doch wunderbar vor, wie es geht.
Alle bekloppt!
Ich kenne dieses Gefühl von „alle bekloppt!“ sehr gut. Ich fühle es öfter mal in Richtung Schulsystem, Lehrer der Kids oder Eltern von Mitschulkindern. Insofern ist dieser Absatz Frau Novemberregen wirklich gut und richtig:
Dann noch einen Termin mit der Hausverwaltung aus rein strategischen Gründen abgesagt, nämlich weil ich mich nicht bis Mittwoch in eine Haltung bringen kann, die nicht „ihr seid doch alle Vollidioten“ ausstrahlt und so eine Haltung ist für Verhandlungen komplett ungeeignet. So ist es ja nicht, niemand wird morgens wach und denkt sich Okay, heute bin ich ein absoluter Vollidiot! Es ist eher so, dass das Verhalten in dem jeweiligen Referenzsystem irgendeinen Sinn ergibt und wenn ich den Sinn nicht verstehe, habe ich dass System noch nicht verstanden, dann fehlen mir noch Informationen. Und wenn ich so verbockt in Gespräche gehe, bekomme ich diese Informationen ganz sicher nicht. Bis Mittwoch habe ich allerdings keine Zeit, mich innerlich wieder komplett unverbockt aufzustellen, dazu brauche ich ein bisschen und es ist zu viel anderes, daher: strategische Absage.
Source: Novemberregen by @novemberregen
Das mal verinnerlichen.
Und jetzt zum Sport
Ansonsten läuft es aktuell gut. Letztes Wochenende war ich an der polnischen Grenze, die Oder besuchen.


Ich bin vom Trainingsstand nicht ganz da, wo ich sein wollen würde aber es wird. Im Juli stehen ca. 250km an, an die Ostsee. Das sind nochmal 100 mehr als am Samstag. Dafür muss ich noch den Sattel am Rad tauschen. Der mitgelieferte verträgt sich nach 100km nicht ganz so gut mit meinem Allerwertesten. Deshalb montiere ich meinen bekannten Sattel, mit dem ich auch „problemlos“ schon 300km am Stück gefahren bin. Das sollte passen.
Arbeit
Hier passiert gerade einiges. Offiziell wird es aber erst nächste Woche angekündigt. Bin aber gespannt und sehr vorfreudig.
Nochmal zum Sport
Über Himmelfahrt werde ich im Frankenjura sein. Das ist ein Wald-Dreieck zwischen Bamberg, Bayreuth und Nürnberg.

Dort werde ich das erste Mal draußen bouldern. Wir werden nicht klettern, nur bouldern. Mal reinfühlen, wie so ein Fels sich in Echt anfühlt 😉. Das Ganze mit dem Camper. Also viel Natur und Luft. 🤞, dass das Wetter halbwegs hält. Und „nebenbei“ werde ich an den Tagen noch etwas arbeiten müssen, denn soviel Ulopp hat ja niemand.
Musik
Empfehlung: Olivia Rodrigo: Tiny Desk Concert www.youtube.com/watch …ohne Einbettung, da ich den ganzen Cookiekram nicht haben möchte.
Robin has an interesting post where he lists all the software he uses on a daily basis and where that software is made/comes from.
I am too lazy to make the same list, but I appreciate the thoughts that reading his list started in my head.
In this post @manton links to Tobi Lütke’s article on AI @ Shopify. I am really sure that using AI can be helpful in certain situations. I don’t like the idea to reflexively reach for AI for all tasks. In the end, where is the fun for that? Because then you really are only a glorified and slow automaton for AI doing things. On the other end I also believe you are doing something wrong if you don’t find the places were AI can support you in what you are doing. There are always parts of the work that can benefit by reaching for AI. If you are not even interested in finding those parts for your specific work, then you are doing it wrong. Curiosity is one of the defining characteristics of a good software engineer, the drive to find out how and why stuff works. And how to make it better.
Die Blase OpenAI wird platzen und Apple wird davon profitieren
Ich habe mal wieder etwas von Ed Zitron gelesen. Erneut zum Thema OpenAI. Laut Ed wird die Blase OpenAI und generative AI platzen, und Auswirkungen auf die ganze Tech Industrie haben. Entschuldige bitte den etwas reißerischen Titel.
Ich habe mit Hilfe von ChatGPT (wie meta 🫣) das Ganze mal hinterfragt und wollte kurz meine Schlüsse teilen. Und warum das gut für Apple 🍎 sein könnte.
Der Artikel von Ed lautet „OpenAI Is A Systemic Risk To The Tech Industry“.
Kurze Zusammenfassung, falls du das nicht lesen willst. Es ist recht lang.
OpenAI hat kürzlich eine Finanzierungsrunde über 40 Milliarden US-Dollar angekündigt, von denen bisher nur 10 Milliarden eingegangen sind. Die restlichen 30 Milliarden sollen bis Ende 2025 folgen, sind jedoch an Bedingungen geknüpft, darunter die Umwandlung von OpenAI in ein gewinnorientiertes Unternehmen. SoftBank plant, 20 Milliarden beizusteuern, allerdings teilweise durch Kredite finanziert, was die Stabilität der Zusagen infrage stellt.
Mit einem geschätzten Jahresumsatz von 4 Milliarden US-Dollar im Jahr 2024 wird OpenAI mit dem 75-Fachen seines Umsatzes bewertet – eine Bewertung, die Zitron als überzogen und spekulativ einstuft.
Außerdem stellt Ed noch dar, wie OpenAI jedes Jahr 40 Milliarden benötigt um überleben zu können. Und SoftBank, der Hauptinvestor muss sich schon sehr strecken, einmalig die 40Mrd. bereitzustellen. (Details dazu im Artikel).
Hier jetzt ChatGPTs Kommentar und Analyse.
Zitrons Analyse wirkt überspitzt, trifft aber in den Kernaussagen ins Schwarze:
• Kosten & Skalierung: Richtig: OpenAI hat hohe variable Kosten pro Nutzer (v. a. bei GPT-4) und ist nicht natürlich skalierbar. Die Monetarisierung über ChatGPT Plus reicht nicht aus, um die Betriebskosten zu decken.
• Finanzierungsrisiko: Korrekt: OpenAI hängt stark von externer Finanzierung (v. a. Microsoft) ab. Ohne diese Subventionen wäre das aktuelle Modell nicht tragfähig.
• Sicherheitsbedenken: Ernstzunehmend: Verkürzte Prüfphasen bei neuen Modellen wurden mehrfach intern kritisiert. Der Zielkonflikt zwischen „schnell liefern“ und „sicher entwickeln“ ist real.
• Systemische Gefahr: Etwas übertrieben: OpenAI ist wichtig, aber nicht alleiniger Pfeiler der KI-Branche. Es gibt Alternativen und Diversifizierung.Kurzfazit: Zitrons Analyse ist polemisch, aber inhaltlich weitgehend fundiert – besonders, was Wirtschaftlichkeit und Sicherheitsrisiken betrifft.
Spätestens Ende 2026 sollte sichtbar sein, dass die Blase platzt. Oder sie ist dann bereits geplatzt. Wir werden es sehen. Aus dem Artikel wird auch klar, warum es eigentlich gar nicht anders gehen kann.
Wenn es so kommt, wie beschrieben, implodieren alle generativen AI Anbieter, wie OpenAI, Anthropic etc. Um dann weiterhin AI nutzen zu können, muss man also selbst AI betreiben können. Das würde heißen, man hat sein eigenes Datencenter, mietet sich Kapazität bei AWS oder Azure oder nutzt andere Möglichkeiten. Für mich heißt das, dass das Betreiben von AI lokal auf dem eigenen Rechner, nur noch wichtiger wird. Und dafür machen sich Apple Computer mit dem Apple Silicon Chips wirklich fantastisch. Apple ist zwar zu blöde Siri und ihre eigene Apple Intelligence richtig hinzubekommen, aber LLMs etc laufen mit Hilfe von Ollama ziemlich gut. Wenn die Tools die man nutzt, also darauf optimiert werden, dann wäre das ein Gewinn für uns alle. Viel viel viel Energiebedarf in den Rechenzentren würde eingespart werden können. Milliarden an Kosten für den Betrieb würde nicht mehr benötigt werden.
Was ich noch nicht weiß/verstehe/sehe: Wie die Weiterentwicklung der AI Lösungen laufen wird. Ich habe Schwierigkeiten mir vorzustellen, dass nach dem Platzen der Blase AI komplett weggeht. Unter anderem, wie eben beschrieben. Aber die Weiterentwicklung der Modelle wird fortgeführt werden.
Vermutlich werden die Chinesen am Meisten davon profitieren, wenn OpenAI hops geht, da sie wirtschaftlich nicht damit verbandelt sind—anders als die meisten nicht chinesischen AI Player.